Autonomous Drones for Emergency Responders
People
Funding
This project is funded by the National Police (Politie) of the Netherlands.
More LinksAbout the Project
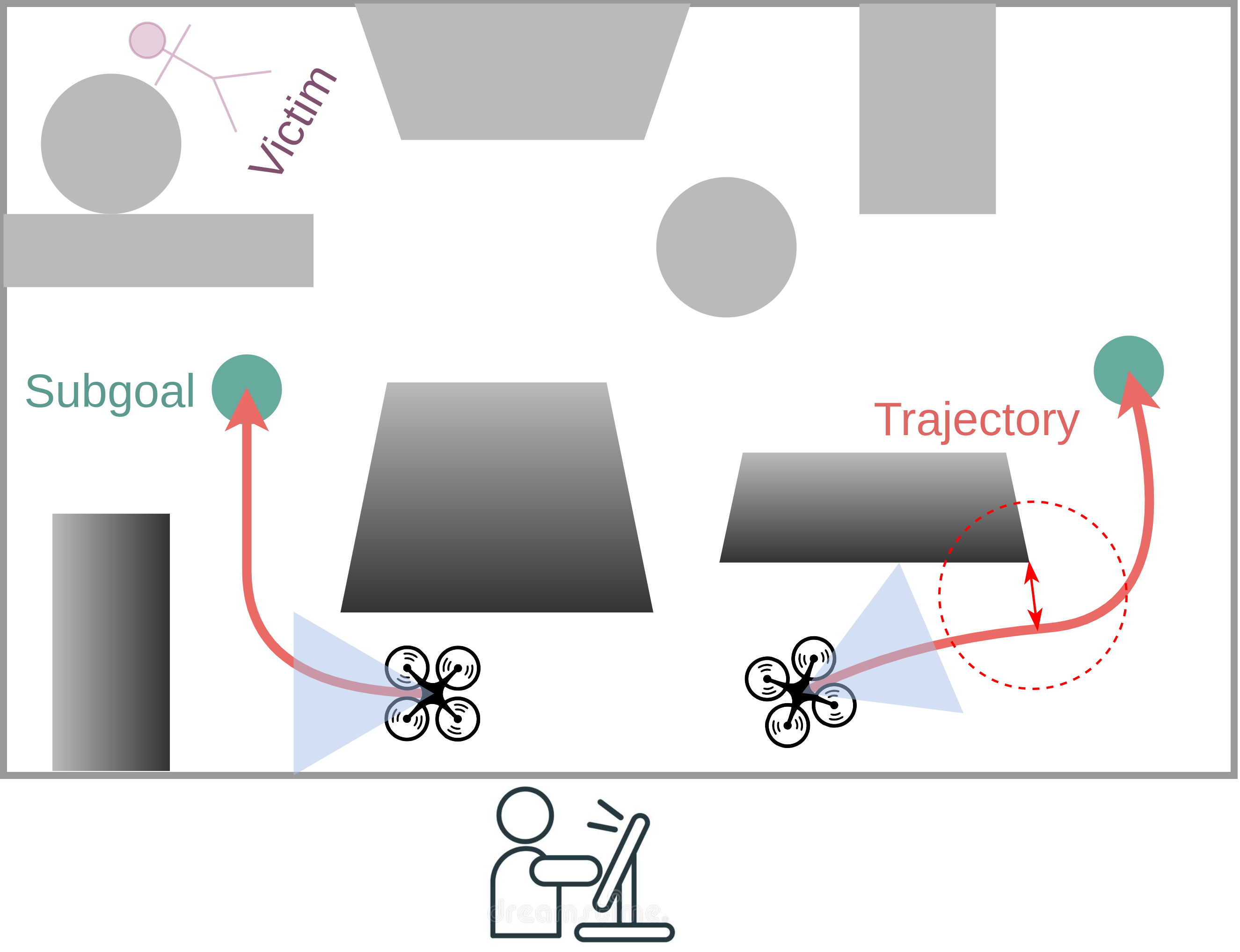
How can autonomous drones support operations of emergency responders such as the police? This project targets scenarios such as search and rescue or reconnaissance in large, unknown and potentially hazardous environments, where it can be difficult or even dangerous for policemen to operate and fulfil the task themselves. In this project we aim to enable drones to operator in such remote environments and gather information required by police operators. We develop methods to control entire teams of drones, so they can fly safely between obstacles and are robust to unexpected disturbances, and can navigate unknown environments to provide the required information.
Related Publications
Where to Look Next: Learning Viewpoint Recommendations for Informative Trajectory Planning
In Proc. IEEE Int. Conf. on Robotics and Automation (ICRA),
2022.